

A custom connector is an integration tool that enables you to push content from unsupported or proprietary knowledge sources directly into Knowledge Hub using secure APIs. Unlike standard connectors that work with predefined platforms, custom connectors provide flexibility for businesses with custom-built platforms or specialized applications, ensuring their unique data can be ingested, updated, and managed seamlessly in the Knowledge Hub.
The custom connector uses APIs to ingest documents into Knowledge Hub, supporting operations like insert, update, and delete. Customers authenticate via OAuth tokens, then push content and metadata including unique document identifiers—through the ingestion API. Advanced features like conditional content parsing, image-to-text extraction, and validation rules ensure robust and accurate integration.
Document API
The Document API is the primary interface for pushing content and metadata from custom-built platforms or unsupported knowledge sources into Knowledge Hub. It enables you to insert, update, and delete documents programmatically, ensuring seamless integration and data consistency.
This API allows organizations to manage their knowledge base dynamically by ingesting documents in real time. It supports both inline text and file-based content, making it suitable for diverse data formats.
This method is a developer effort. It required knowledge of REST APIs and programming ability to send files using an API.
-
The maximum file size of an individual file is 30 MB.
-
You can transfer up to 50 files at a time.
These limits apply to all file upload operations within the Document API. Ensure that your implementation validates these constraints before initiating transfers to avoid errors.
Endpoint
POST /ingestion-service/v1/documents
Authentication
To use the Document API, include an access token in the request header. This token is obtained by exchanging credentials provided by NiCE through the authentication process. Follow the Getting Started instructions on the Developer Portal to generate your access token.
Once generated, include the token in all API calls. This ensures that NiCE CXone can verify the request and prevent unauthorized access.
For more details on API authentication and authorization, refer to the NiCE CXone documentation.
Pre-requisites for Document API Execution
-
You must have your Knowledge Hub license enabled.
-
You must have a knowledge base and data source created in the Knowledge Hub. For details, refer to the Creating a Knowledge Base topic.
-
You must have knowledgeHubId and dataSourceId. For details on retrieving knowledgeHubId and dataSourceId refer to the Fetch IDs topic.
Request Body Parameters:
|
Parameter |
Type |
Description |
| clientToken | string | UUID v4 token to uniquely identify and track the request. |
| dataSourceId | string | UUID of the data source where documents will be ingested. |
| knowledgeHubId | string | UUID of the Knowledge Hub instance. |
| documents | string |
JSON array of document objects. Each object must include:
|
| documentParseConfig | string |
Optional JSON defining parsing rules for conditional content visibility. This field only works with HTML documents. It uses the HTML tags and CSS class names you specify to identify and separate different parts of the content.
contentTags + permissionAttributeNames: Tags classify documents; permissions control access. cssClassName + permissionAttributeNames: Styling can indicate permissions, for example, restricted documents appear grayed out. |
Understanding the document Object
The document object is part of the documents array in the request body. It contains two main sections:
-
content
-
The content section provides the actual document data (text or file) that needs to be ingested.
-
Parsing starts here because the system reads the raw content and applies rules like image parsing (parseImage) or conditional visibility.
-
It consists of the following fields:
-
documentIdentifier: A unique identifier for the document (for example, "my-document-001.txt"). Used for insert, update, and delete operations.
-
For update operations, you must use the documentIdentifier and include the updated content or metadata in your request.
-
-
deleted: Boolean flag
-
If set to false, the document will be inserted or updated.
-
If set to true, the document will be deleted.
-
For delete operations, you must provide only the documentIdentifier and set deleted to true.
-
-
parseImage: Boolean flag to enable image parsing:
-
If set to true, the API extracts text from images using LLM
 Large Language Model. A type of AI that processes, understands, and generates human language based on context..
Large Language Model. A type of AI that processes, understands, and generates human language based on context.. -
If set to false, the API skips image parsing.
-
-
inlineContent: Defines the type and actual content of the document:
-
type: "TEXT" (indicates text content).
-
textContent.data: The actual text string (e.g., "This is a sample document text content.").
-
-
byteContent: Defines the raw binary data of the document that is uploaded. It is usually represented as a Base64-encoded string in the request to payload.
-
-
-
metadata
The metadata section provides contextual attributes that make the document searchable and properly indexed in Knowledge Hub. Mandatory fields like PagePath and Title ensure the document is correctly linked and displayed.
Additional attributes, for example, author, createdDate, and so on improve filtering and retrieval. Validation rules check metadata integrity before ingestion, preventing incomplete or malformed data.
-
inlineAttributes: An array of key-value pairs representing metadata fields. Each object includes:
-
key: Metadata field name (for example, "author", "createdDate", "PagePath", "Title").
-
value:
-
stringValue: Actual value (for example, "Test User", "2023-03-15", "https://example.com/sample.html").
-
type: Data type (e.g., "STRING").
-
-
Validation will fail if the mandatory metadata fields, PagePath and Title, are missing or empty.
-
Supported Response Code
|
Code |
description |
|---|---|
| 200 | Success – Documents accepted for processing |
| 400 | Validation Error – Missing required fields |
|
401 |
Unauthorized – Invalid or missing token |
| 404 | Not Found – Invalid API path |
| 500 | Internal Server Error – Unexpected issue |
Example: Success Response
{
"documentDetails": [
{
"documentIdentifier": "doc001",
"status": "SUBMITTED_SUCCESSFULLY",
"statusReason": "Successfully parsed",
"updatedAt": "2025-02-21T11:29:47Z"
}
]
}
Example: Validation Error
{"message": "Missing required field: knowledgeHubId",
"error": "INVALID_INPUT"
}
Snapshot API
The Document Snapshot API retrieves a snapshot view of successfully ingested documents in the Knowledge Base. It returns document metadata such as Filename, Last ingestion timestamp, and Status. The API supports pagination with a default page size of 25 documents.
Endpoint
POST /ingestion-service/v1/{khId}/documents/snapshot
Request Body Parameters and Headers:
|
Field name |
Location | Required |
Description |
| khId | Path | Yes | Unique identifier of the Knowledge Hub. |
| Content-Type | Header | Yes | Content type of the request.application/json |
| X-B3-Traceid | Header | Yes | Trace ID for request tracking. |
|
X-B3-Spanid |
Header | No | Span ID for distributed tracing. |
| dataSourceId | Body | Yes | Identifier of the data source from which documents were ingested. |
| nextPageToken | Body | No | Token for fetching the next page of results (used for pagination). |
Supported Response Code
|
Code |
description |
|---|---|
| 200 | Success – Snapshot retrieved |
| 400 | Bad Request – Invalid input |
|
401 |
Unauthorized – Invalid or missing token |
| 404 | Not Found – Invalid API path |
| 500 | Internal Server Error – Unexpected issue |
Example: Success Response
{
"documents": [
{
"documentIdentifier": "financial-report.pdf",
"filename": "financial-report.pdf",
"lastUpdatedTimestamp": "2025-06-15T12:34:56Z",
"ingestionStatus": "INDEXED"
},
{
"documentIdentifier": "doc-001-user-guide.txt",
"filename": "user-guide.txt",
"lastUpdatedTimestamp": "2025-06-15T11:20:30Z",
"ingestionStatus": "INDEXED"
}
],
"nextPageToken": "eyJuZXh0VG9rZW4iOiJhYmNkZWYxMjM0NTYifQ=="
}
API Throttling
Both APIs have rate limits. If you send too many requests too quickly, they may be throttled. It is recommended to wait for 30 seconds to 1 minute between large batch requests, for example, 30–50 documents.
If your files are large, you should reduce the number of files you send in one request. For example, if each file is around 30 MB, try sending only 10 files at a time to avoid issues.
Creating a Knowledge Base
Follow the steps below to configure the knowledge base in Knowledge Hub to use a custom knowledge source. This generates the necessary IDs for the knowledge base that you must include in the API call that transfers files.
Creating the knowledge base is done by NiCE Professional Services (PS). If you do not yet have a knowledge base, contact PS. Only PS can create new knowledge bases.
- In NiCE CXone, click the app selector
 and select General > AI Studio > Knowledge Hub.
and select General > AI Studio > Knowledge Hub. -
Click the knowledge base you want to add custom knowledge source to.
-
If you don’t have knowledge base, navigate to top right corner and click on Create New KB.
-
Provide the Knowledge Base Name.
-
Click the Knowledge Base Source drop-down, select Custom.
-
Click Submit.
-
Fetch IDs
To transfer files with the Knowledge Hub API, you must include two IDs:
-
Data Source ID (DS ID): Unique ID string for the custom knowledge source. This tells the API where to pull content from.
-
Knowledge Base ID (KB ID): Unique ID string for the knowledge base you configured. This tells the API where to push content to.
You can obtain these IDs in the following ways:
-
Retrieve KB ID from the Knowledge Hub UI:
-
In NiCE CXone, click the app selector
and select General > AI Studio > Knowledge Hub. -
Locate the required knowledge base in the list.
-
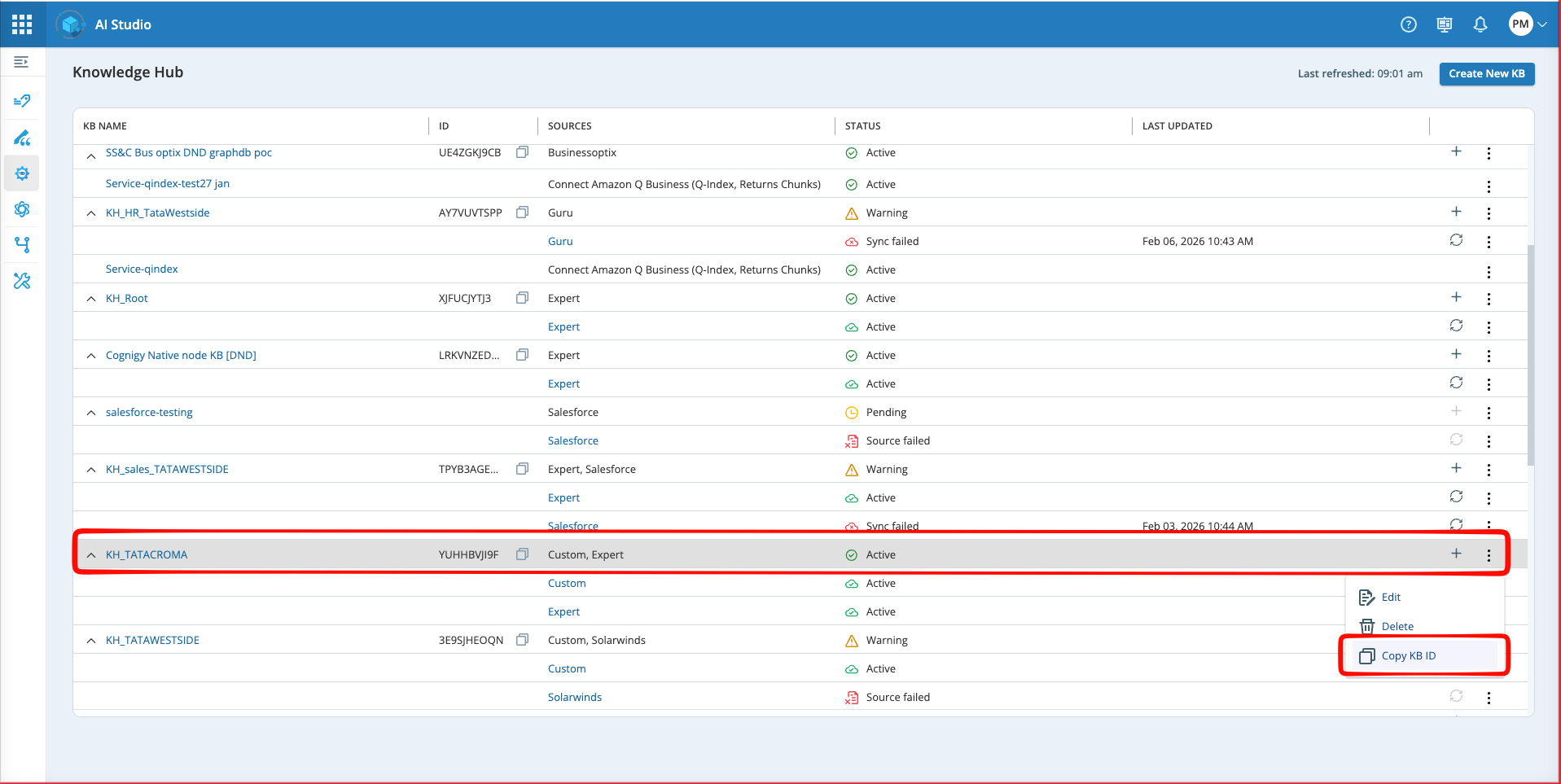
Click the More options menu
 at the end of the row.
at the end of the row. -
Select Copy KB ID from the menu.
-
-
Retrieve DS ID from the Knowledge Hub UI:
-
In NiCE CXone, click the app selector
and select General > AI Studio > Knowledge Hub. -
Locate the required knowledge base you need and expand it to view its data sources.
-
Locate the required data source in the list (for example, Custom).
-
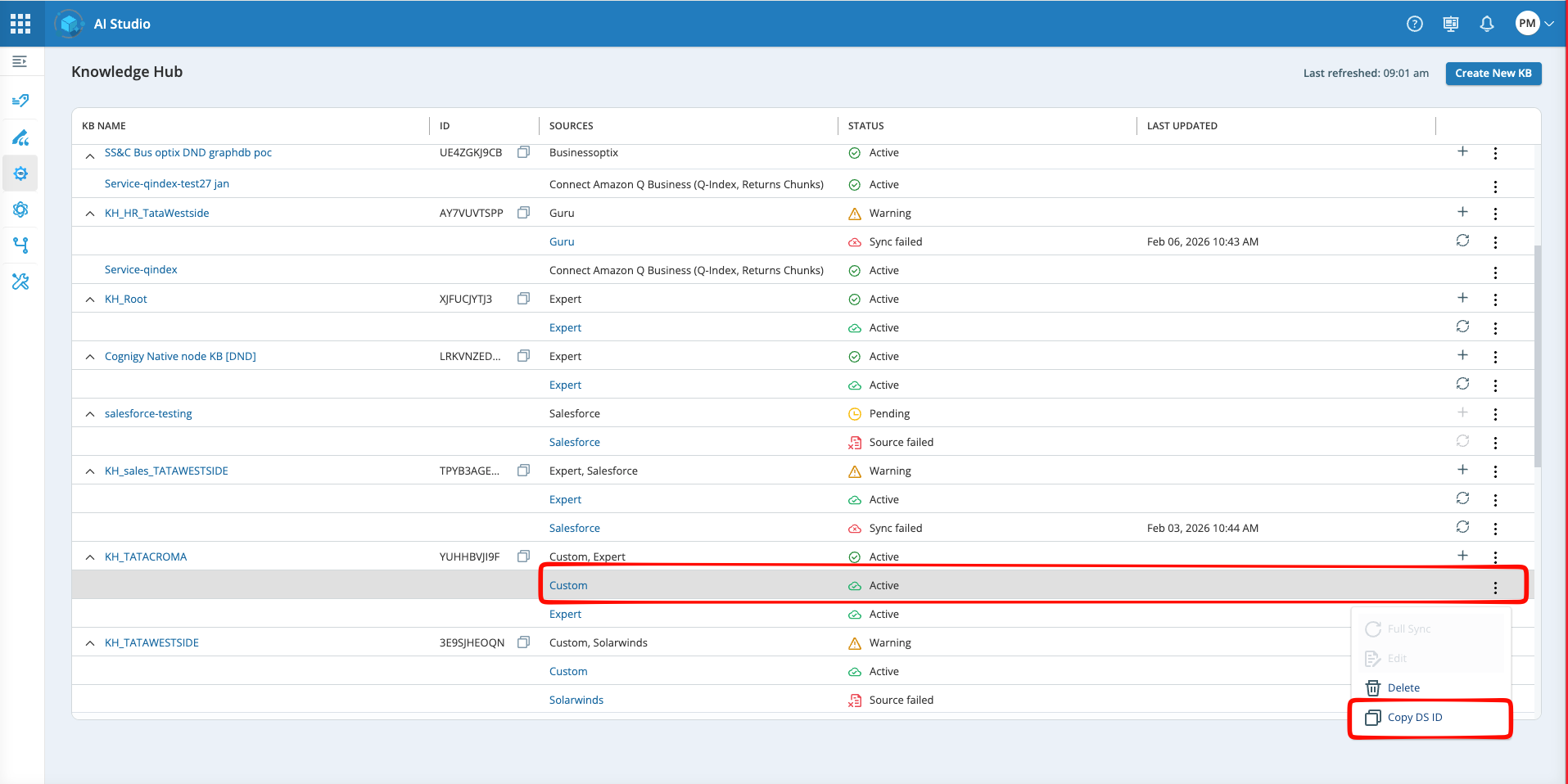
Click the More options menu
at the end of the row. -
Select Copy DS ID from the menu.
-
-
Alternatively, retrieve them programmatically or using Postman:
-
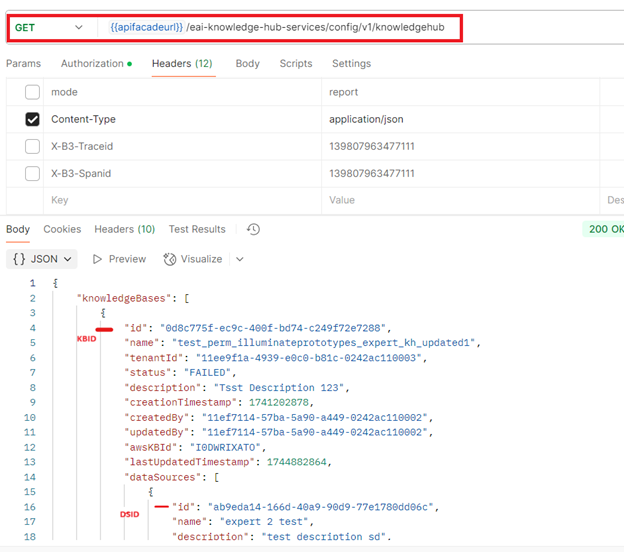
Send a GET request to https://api-na1.niceincontact.com/eai-knowledge-hub-services/config/v1/knowledgehub
-
Include the following headers:
curl --location 'https://api-na1.niceincontact.com/eai-knowledge-hub-services/config/v1/knowledgehub' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer <CXONE token>'
-
In the response, locate the entries where sourceType is set to CUSTOM, and retrieve the corresponding KB ID and DS ID.
-
-
Contact Professional Services or your Technical Account Manager:
-
If you cannot retrieve the IDs, contact your Professional Services or your Technical Account Manager for assistance.
-
The knowledgeHubId and dataSourceId remain valid as long as the associated Knowledge Base and Data Source exist. If either is deleted, these IDs will no longer be usable.